win10讲述人无法朗读unicode混合语言怎么办?解决方法
更新时间:2026-03-27 10:44
windows系统内置的讲述人在处理包含unicode编码的混合语言文本时(如英文与日文混合),可能会出现识别中断或跳过非默认语种字符的情况。如果讲述人在朗读过程中遇到类似“We are soon arriving at: こまの”这种句子,往往只能流畅读出英文部分,而对于后续的unicode字符则会直接忽略。这种现象通常源于语音引擎的语言包限制,通过手动安装多语言语音资源并切换引擎可以改善朗读体验。
检查并安装扩展语言包
目前的讲述人组件默认仅调用当前系统主语言的语音引擎。如果文本中包含此语种之外的unicode字符,系统会因为缺乏对应的语音库而选择跳过。
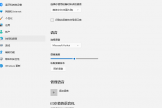
进入语言设置:打开windows设置,依次进入“时间和语言”>“语音”。
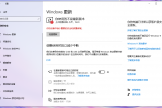
添加语音资源:在“管理语音”部分,点击“添加语音”,搜索并安装文本中涉及的语种(如日语)。
重启讲述人:安装完成后,建议重启讲述人功能,让系统重新扫描并加载新安装的语音合成组件。
切换讲述人语音引擎
部分老旧的语音引擎对unicode的兼容性较差,容易导致程序闪退或字符跳过。
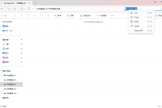
选择多语言语音:在讲述人设置界面中,下拉查找“选择语音”列表。
匹配自然声音:尝试切换为带有“Natural”后缀的语音(如Microsoft Nanami Online),这类基于云端的引擎对混合语言的识别准确率更高。
这种朗读中断并非由于系统文件损坏,而是因为本地语音库无法解码特定编码格式的文本。如果安装语言包后仍无法解决,说明当前的讲述人架构尚不支持在同一个句子中实现无感知的语种自动切换,这时建议将需要朗读的内容按语种分段处理。