网关性能优化 – (一)HTTP连接池优化提升服务性能
1、背景
Webgate服务在联调期间,发现用户请求无响应的问题。现象:Webgate服务在启动后,随着用户请求不断的访问(用户通过浏览器发送请求),一段时间后,发现请求开始打转(菊花^_^),没有返回。服务重启后正常,访问一段时间又重现。
小贴士:Webgate是个什么服务?
Webgate是基于zuul1.0实现的网关服务,包括了鉴权、限流、熔断、负载均衡、http请求转发等功能。核心就是请求路由,即http请求转发。
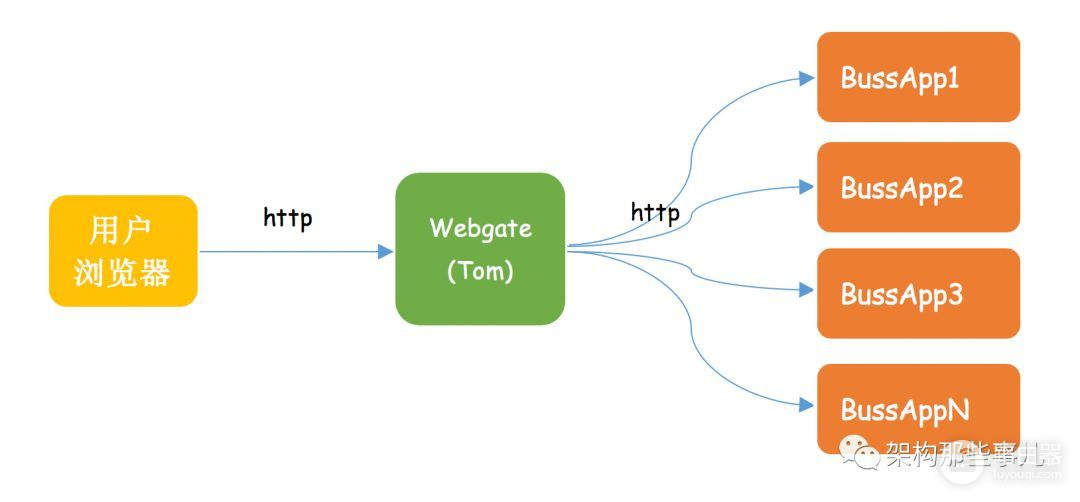
服务模块调用示意图
2、结论先行
经过一系列的排查定位到由于http连接池相关参数设置不合理及http异常请求连接没释放,从而导致连接数耗尽,出现了请求打转的现象。
看了服务部署图、问题小伙伴是不是会有如下的疑问呢:
①请求无响应如何定位到是Webgate的问题,不是BussApp的问题?
②Webgate这么多功能,如何定位到是http连接池的问题呢?
那么下边我们将重现如何定位问题及解决问题的过程。
3、定位过程
1、逐一排除法,缩小问题范围,确定问题服务。
通过服务调用模块示意图,我们知道当用户浏览器端无响应时,要么是Webgate的问题,要么是BussApp的问题。在通过webgate访问出问题后,直接访问BussApp是可用的,那么很快可以定位到是webgate出了问题。解释了疑问①
2、聚焦问题服务,查看日志有无明确提示。
确定了是webgate的问题后,继续深入查看导致webgate服务无响应的原因:
首先查看日志,无可疑异常日志打印。
3、根据现象猜测可能原因,逐一排除,确定问题代码。
猜测可能的原因:
- 怀疑线程进入死循环了,查看了cpu。发现cpu的每个核利用率均不高。
- 查看系统资源利用情况 cpu io mem net均正常。
- 怀疑full gc?查看,发现也没有full gc。(full gc产生会导致应用程序暂停响应)
- 怀疑线程等待、阻塞了、死锁 查看堆栈信息(jstack)。如图发现了问题。
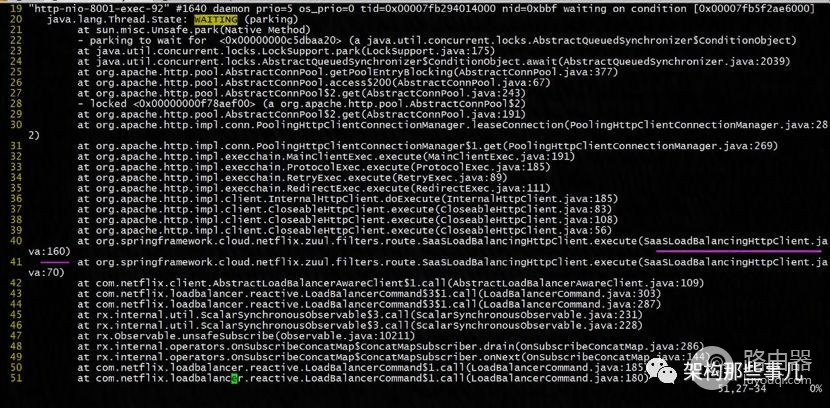
WAITING 状态的线程 ,发现在运行到SaaSLoadBalancingHttpClient.execute() 时等待了。这个时候就欣喜了 。这个是应用的代码发送http请求。
继续往上看
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection
很明显是去连接池获取连接对象,到此我们定位到是http连接池的问题了。
小贴士:
深入思考的小伙伴会问 几千行的堆栈信息里 你是怎么找到的?
其实只要对 Java的线程的生命周期,及线程的每个状态理解透彻了,也就知道在什么情况下该关心什么状态的线程。
再比如:有个CPU使用率100% ,那需要关注什么状态的线程答案是:RUNNABLE
4、聚焦问题代码,深挖原因。
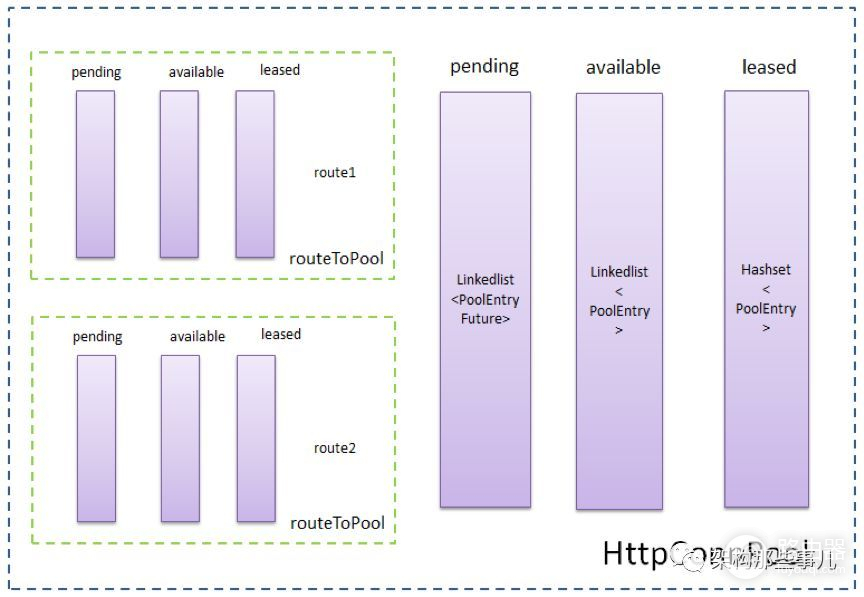
为什么会一直等待呢? 框架中我们使用了http连接池[了解http连接池的原理]
如图连接池的一个结构图,关于连接池如何建立连接、分配连接、回收连接、保持连接这里暂不进行说明。
小贴士:了解下http连接池的三个超时时间相关参数
connectionRequestTimeout
#设置从connect Manager获取Connection 超时时间,单位毫秒。这个属性是新加的属性,因为目前版本是可以共享连接池的。需要设置,默认-1.无限长等待。默认为-1,意味着无限大,就是一直阻塞等待。 从连接池中获取连接的超时时间,超过该时间未拿到可用连接, * 会抛出org.apache.http.conn.ConnectionPoolTimeoutException:Timeout waiting for connection from pool
#设置建议 设置500ms即可,不要设置太大,这样可以使连接池连接不够时不用等待太久去获取连接,不要让大量请求堆积在获取连接处,尽快抛出异常,发现问题。
connectTimeout
#连接上服务器(握手成功)的时间,超出该时间抛出connecttimeout
#设置建议:根据网络情况,内网、外网等,可设置连接超时时间为2秒,具体根据业务调整
socketTimeout
#服务器返回数据(response)的时间,超过该时间抛出read timeout
#设置建议:需要根据具体请求的业务而定,如请求的API接口从接到请求到返回数据的平均处理时间为1秒,那么读超时时间可以设置为2秒,考虑并发量较大的情况,也可以通过性能测试得到一个相对靠谱的值。socketTimeout有默认值,也可以针对每个请求单独设置。
查看我们代码发现第一个参数没有设置 ,所以一直等待。设置超时时间为500毫秒
builder.setConnectionRequestTimeout(500);
设置超时时间 ,连接用完后。查看日志抛出异常
org.apache.http.conn.ConnectionPoolTimeoutException: Timeoutwaiting for connection from pool
为什么从连接池里get 不到connection对象?池连接数太小,还是连接数耗尽了?
小贴士:看http连接池的其它几个连接相关参数
maxConnTotal
#maxConnTotal 是整个连接池的大小,根据自己的业务需求进行设置
maxConnPerRoute
#是单个路由连接的最大数,可以根据自己的业务需求进行设置。比如maxConnTotal =200,maxConnPerRoute =100,那么,如果只有一个路由的话,那么最大连接数也就是100了;如果有两个路由的话,那么它们分别最大的连接数是100,总数不能超过200
#Http连接参数设置建议:
根据“利尔特法则”可以得到简单的公式:
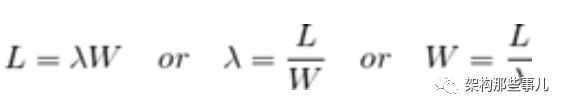
简单地说,利特尔法则解释了这三种变量的关系:L—系统里的请求数量、λ—请求到达的速率、W—每个请求的处理时间。例如,如果每秒10个请求到达,处理一个请求需要1秒,那么系统在每个时刻都有10个请求在处理。如果处理每个请求的时间翻倍,那么系统每时刻需要处理的请求数也翻倍为20,因此需要20个线程。连接池的大小可以参考 L。
qps指标可以作为“λ—请求到达的速率”,由于httpClient是作为http客户端,故需要通过一些监控手段得到服务端集群访问量较高时的qps,如客户端集群为4台,服务端集群为2台,监控到每台服务端机器的qps为100,如果每个请求处理时间为1秒,那么2台服务端每个时刻总共有 100 * 2 * 1s = 200 个请求访问,平均到4台客户端机器,每台要负责50,即每台客户端的连接池大小可以设置为50。
当然实际的情况是更复杂的,上面的请求平均处理时间1秒只是一种业务的,实际情况的业务情况更多,评估请求平均处理时间更复杂。所以在设置连接数后,最好通过比较充分性能测试验证是否可以满足要求。
还有一些Linux系统级的配置需要考虑,如单个进程能够打开的最大文件描述符数量open files默认为1024,每个与服务端建立的连接都需要占用一个文件描述符,如果open files值太小会影响建立连接。
还要注意,连接数主要包含maxTotal-连接总数、maxPerRoute-路由最大连接数,尤其是maxPerRoute默认值为5,很小,设置不好的话即使maxTotal再大也无法充分利用连接池。
默认设置的小 10 和 5,然后调大 ,只是推迟了服务挂的时间。
打开http连接池的debug日志 ,发现httpclient大部分能正常回收 但是可用的越来越少 ,当可用为0 就是服务不可用的时候。
2018-08-09 16:37:10,465 DEBUG PoolingHttpClientConnectionManager:288 - Connection leased:[id: 98474][route:{}->http://tenantweb-prd1.ypubtanent.svc.gz.n.jd.local:80][total kept alive:0; route allocated: 2 of 50; totalallocated: 2 of 200]
2018-08-09 16:37:10,497 DEBUG PoolingHttpClientConnectionManager:326 - Connection released: [id:98474][route: {}->http://tenantweb-prd1.ypubtanent.svc.gz.n.jd.local:80][totalkept alive: 0; route allocated: 1 of 50;total allocated: 1 of 200]
2018-08-09 16:37:10,535 DEBUG PoolingHttpClientConnectionManager:326 - Connection released: [id:98473][route: {}->http://tenantweb-prd1.ypubtanent.svc.gz.n.jd.local:80][totalkept alive: 0; route allocated: 0 of 50; total allocated: 0 of 200]
2018-08-09 16:37:12,201 DEBUG PoolingHttpClientConnectionManager:414 - Closing expired connections
2018-08-09 16:37:17,201 DEBUG PoolingHttpClientConnectionManager:414- Closing expired connections
2018-08-09 16:37:22,201 DEBUG PoolingHttpClientConnectionManager:414 - Closing expired connections
证实连接没释放。(不得不感叹写http连接池的大牛们牛叉,log打印的可读性极好)为什么连接没释放?
查看TCP状态 lsof -i -a -p $java_pid
java 6408 michael 381u IPv6 11136490 0t0 TCP localhost:46768->localhost:webcache(CLOSE_WAIT)
java 6408 michael 382u IPv6 11136494 0t0 TCP localhost:46770->localhost:webcache(CLOSE_WAIT)
java 6408 michael 383u IPv6 11135941 0t0 TCP localhost:46790->localhost:webcache(CLOSE_WAIT)
java 6408 michael 384u IPv6 11134910 0t0 TCP localhost:46792->localhost:webcache(CLOSE_WAIT)
java 6408 michael 385u IPv6 11137709 0t0 TCP localhost:46802->localhost:webcache(CLOSE_WAIT)
java 6408 michael 386u IPv6 11135974 0t0 TCP localhost:46804->localhost:webcache(CLOSE_WAIT)
可以看到链接都是处于close_wait状态。
查了一些资料得知:
close_wait状态是通信双方中的服务端主动关闭了链接,于是请求发起方的操作系统收到了FIN指令,然后在系统层面将链接状态调整为close_wait状态,接着请求发起方的应用程需要再执行关闭动作,然后链接才能释放。如果请求方的应用没有执行关闭动作,那么connection会一直处于close_wait状态,直到应用程序重启,这个close_wait状态的链接才能释放。
所以从这里看出,如果应用没有对链接资源进行及时的资源释放,就会导致链接泄漏,随着时间发展,应用的可用链接资源就越来越少,当链接资源都被消耗光后,就会出现无可用连接故障。
查看代码怀疑异常时连接没释放。
try{
httpResponse =this.delegate.execute(httpUriRequest);
logger.info("this.delegate.executeafter");
status = httpResponse.getStatusLine().getStatusCode();
}catch(Exception e){
//异常请求释放连接
httpUriRequest.abort();
}
httpUriRequest.abort();
# 确保低级别资源释放 中止异常请求
修复后再上线,服务持续正常。
4、小结
1、http连接池的原理理解和连接参数、超时时间参数如何合理设置。
2、遇到问题的解决思路:缩小问题范围、聚焦具体问题服务;怀疑问题、验证怀疑;定位问题工具的运用(日志、相关查看资源命令要熟悉)











