解决Kubernetes故障切换问题(如何解决不同路由器切换的问题)
服务和集群肯定会在Kubernetes上出问题,SRE或运维人员通常会在半夜被要求手动修复。虽然Kubernetes确实提供了一种故障切换机制,但它并不是以这样一种方式自动化的——在集群或服务出现故障时,服务会立即转移到副本集群配置,在那里它们会恢复功能。
Buoyant的高级软件开发人员Alejandro Pedraza在一篇博客中写道,Linkedr的一项新的自动故障切换功能使Linkedr能够自动将所有流量从故障或无法访问的服务重定向到该服务的一个或多个副本,包括其他集群上的副本。“正如你所料,任何重定向的流量都能维持Linkedr对应用程序的安全性、可靠性和透明度的所有保证,甚至可以跨越由开放互联网分隔的集群边界。”
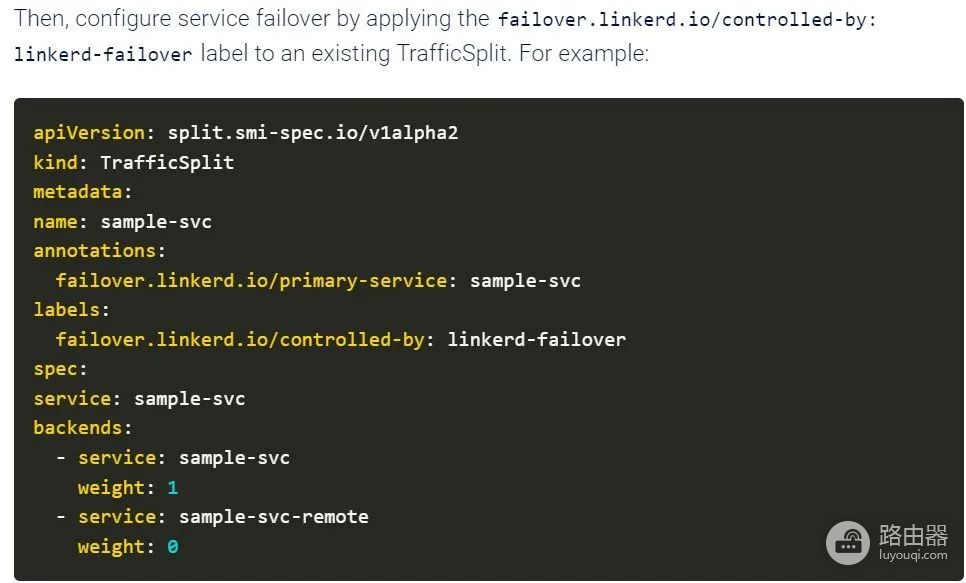
其他领先的服务网格提供商也为Kubernetes的故障切换缺陷提供了类似的修复,Istio和HashiCorp提供了类似的修复。
松一口气
对于Linkedr用户来说,这种故障功能应该会让在Kubernetes环境中工作的运维团队松一口气。这是因为它不需要运维团队“在半夜不得不去修复Kubernetes集群,而是通过自动重新路由应用流量而不需要任何代码更改或重新配置。”企业管理协会(EMA)的分析师Torsten Volk表示。
Linkedr的联合创始人William Morgan也是Buoyant的首席执行官,他表示,有了Linkedr新的自动故障切换功能,集群运维人员可以在服务级别以一种完全自动化且对应用程序透明的方式配置故障切换。这意味着,如果一个组件出现故障,该组件的所有流量将自动路由到一个复制副本,“应用程序不知道这一点”。
“如果该副本位于不同地区的不同集群中,或者甚至位于不同的云中,Linkedr的双向TLS实施意味着,即使流量现在正在通过开放互联网,也能保持完全安全。这是Linkedr用户长期以来一直要求的。”
就Istio而言,Istio“一段时间以来”一直支持Kubernetes的故障切换自动化,Solo的全球现场首席技术官副总裁Christian Posta说,并用Solo.io Gloo Mesh“自动化了所有配置”——“这主要源于Envoy所具有的位置和优先级感知负载均衡。”
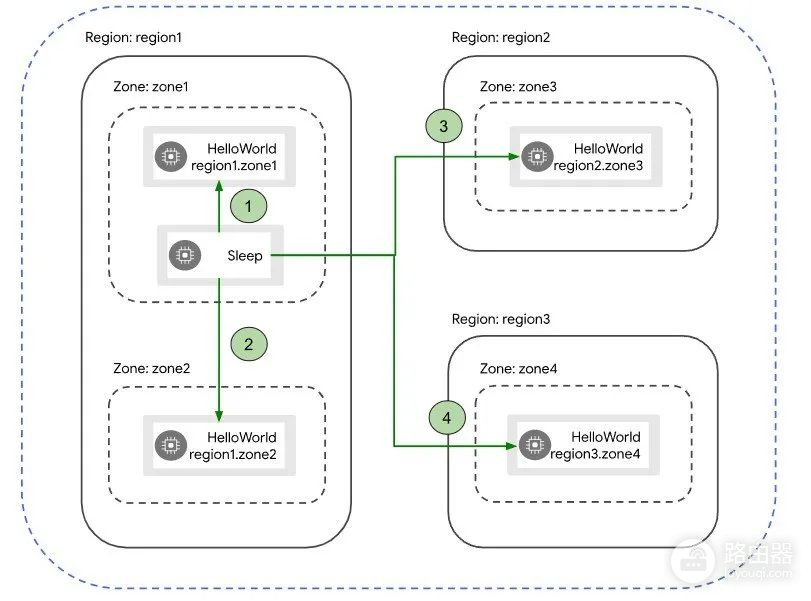
HashiCorp也实现了一段时间的故障切换功能的自动化,这在其文档中有所描述。
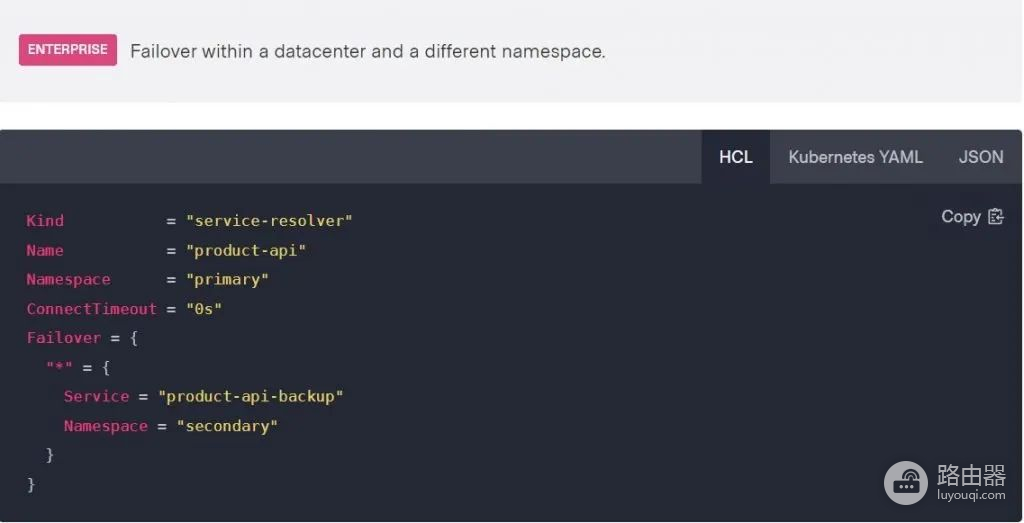
Volk说,Kubernetes的故障切换功能自动化的推动支持了策略驱动应用程序放置的最初概念。通过这种方式,“DevOps团队不再需要根据应用程序需求精确定义特定的应用程序环境,相反,开发人员可以在应用程序代码中声明应用程序需求,然后服务网格匹配这些需求。”
简单概念
主要问题是Kubernetes在发生故障时不提供自动故障切换功能。Volk说,当Kubernetes上的服务和集群出现故障时,“DevOps团队通常必须更改应用程序代码,以特定于底层云基础设施的方式更改流量路由。这意味着,你需要编写不同的代码,将工作负载路由到AWS、Azure、Google Cloud或其他特定平台上的集群或在这些集群之间。”
实际上,故障切换的概念很简单。Morgan说:“如果一个组件出现故障,将所有发送到该组件的流量发送到其他地方(通常在另一个集群中)的副本。对于希望使用故障切换来提高应用程序恢复能力的DevOps团队来说,最大的挑战之一就是Kubernetes本身没有提供任何自动化解决方案。因此,你可以跨区域部署应用程序组件的副本,但它们之间的故障切换由你决定。更糟糕的是,如果你希望能够对单个服务进行故障切换,应用程序需要了解如何在发生故障时向不同的副本发送通信量。这会将应用程序问题与平台问题混为一谈,并导致维护问题。”
Mogan说,Linkerd中的新故障切换功能是在现有Kubernetes和Linkerd功能(如健康探测器和SMI流量拆分)的基础上构建的,并引入了最少的新机器和配置表面积。“正是这一设计原则,使得Linkeder在很大程度上成为运维最简单的服务网格。这是我们对用户承诺的一部分:Kubernetes已经足够复杂了;服务网格不必如此。”
原文链接:
https://thenewstack.io/the-rush-to-fix-the-kubernetes-failover-problem/