获取给定网页上的所有链接(怎样获取网页上所有下载链接)
小编:芯水
更新时间:2022-09-01
感觉这个试过以后,那些个严禁复制网页内容的就不再是个烦恼了。每个网页右键会出现一个查看网页源代码的选项,看看都有些什么,这对于理解下面的代码是有用处的。
注意看类似这些行Community。代码里的find字符"a"和get的"href"方法主要作用就在这里。
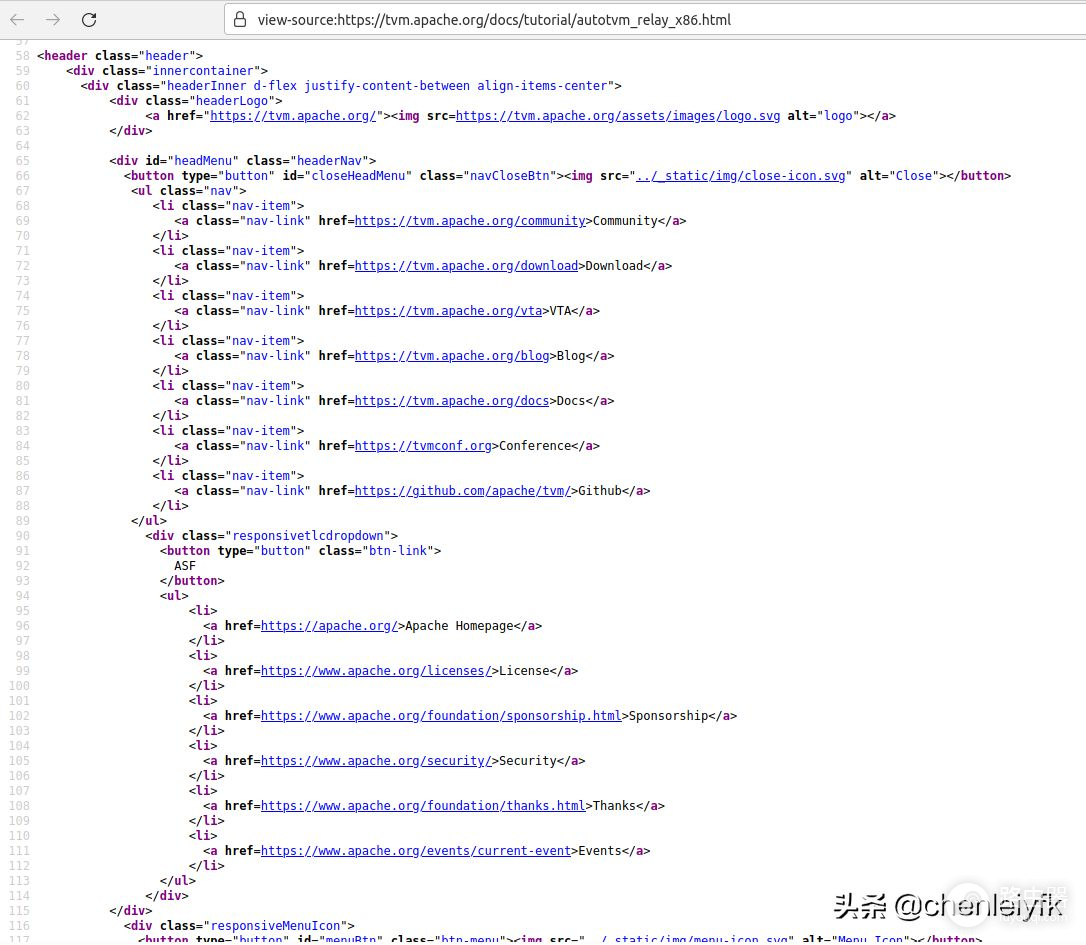
网页源代码
直接上代码吧:
import requests as rq
from bs4 import BeautifulSoup
url = input("Enter Link: ")
if ("https" or "http") in url:
data = rq.get(url)
else:
data = rq.get("https://" + url)
soup = BeautifulSoup(data.text, "html.parser")
saved = open("myLinks.txt", 'w')
for link in soup.find_all("a"):
print(link.get("href"))
saved.writelines(link.get("href"))
saved.writelines("\n")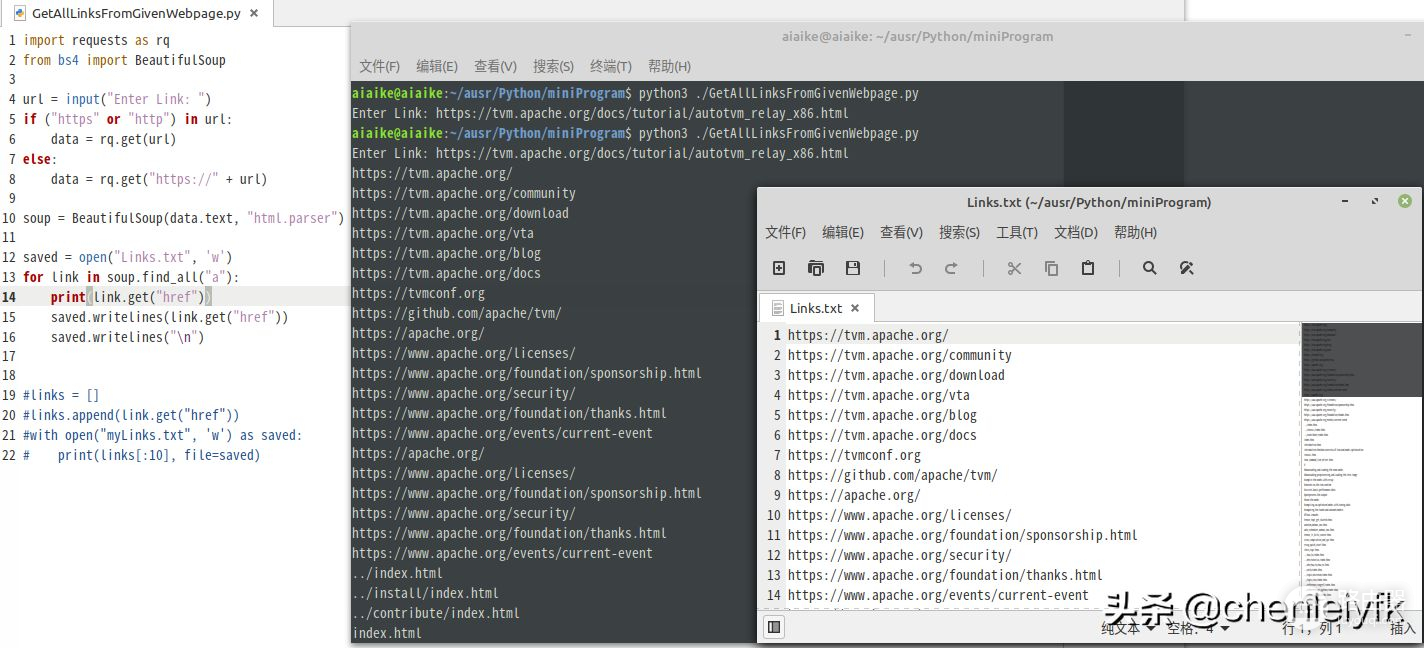
运行示意和输出的文件













