Dubbo负载均衡和路由规则的区别
哈喽,大家好,我是强哥。
大家知道,强哥之前有一篇推文Dubbo也支持基于应用粒度的服务发现机制啦中说到,Dubbo2.x版本目前大都还是使用接口粒度的服务发现机制。
强哥的朋友最近就遇到一个问题。有如下情况:代码仓库中有一套使用Dubbo2.x编写的微服务代码CodeW,其中有一个接口方法algoCompute(Map map),这个方法可以根据传入的Map内部信息的不同,加载不同的算法模型进行计算,以此来达到同一套代码可以根据请求参数的不同处理不同需求的目的。
现在我们有两个服务集群E1和E2,两个集群中的服务使用的代码都是CodeW。但是集群E1只可以支持加载算法模型A的调度,集群E2只可以支持算法模型B的调度。此时就会有一个问题,集群E1和E2提供在Dubbo上的接口algoCompute(Map map)其实在服务提供这层面是有区别的,都是同一个方法的提供者(因为Dubbo2.x版本目前还是使用接口粒度的服务发现机制)。
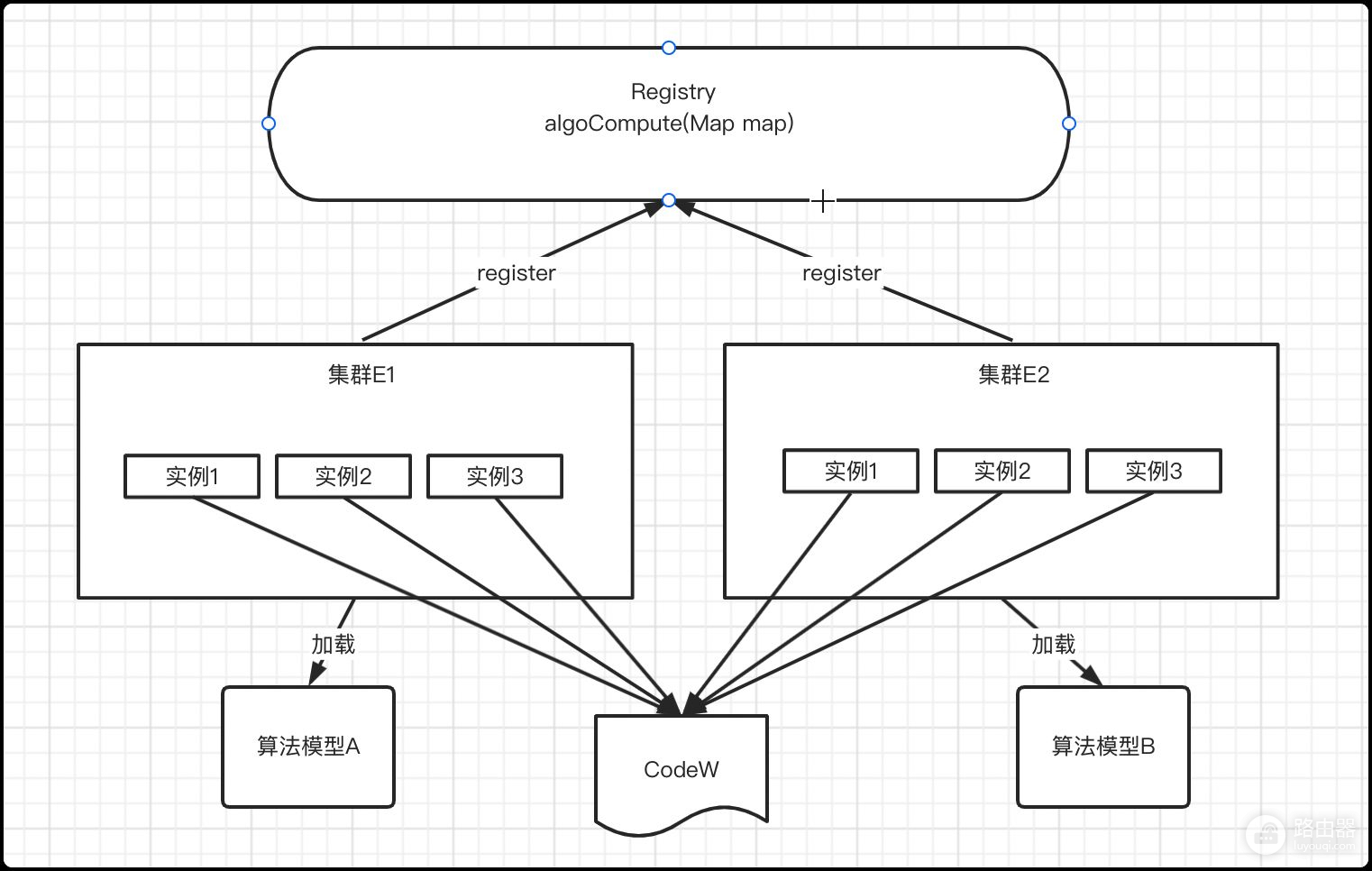
也就是说,如果有一个服务消费者C想要通过algoCompute(Map map)方法只获取集群E1的算法A的结果如果没有经过额外的配置是不可能的。因为消费者在调用algoCompute(Map map)的时候,很可能请求会打到集群E2上,导致提供了算法模型B的运算结果。
那么,要怎么处理这样的问题呢?
我的这个朋友在经过一番思考后,想到能不能使用一致性hash的方式来处理这个问题呢?比如,我们通过配置一致性hash,使得服务消费者C的请求都打到集群E1对应的服务实例上。而其他消费者也通过请求hash,达到对应的服务实例上。
额,强哥听到这种解决办法后,马上提出了质疑,且不说一致性hash在微服务中主要处理的应用场景,就一致性hash本身来说,如果服务的下线,就会导致请求打到其他服务上,如果消费者C的请求经过一致性hash重新计算后都还是打到同一个集群E1上还好说,但是如果就打到不同的集群E2上,那问题就大了。
而会有这个想法,其实还是没有弄懂负载均衡和路由规则的关系。
路由转发规则
路由规则简单来讲就是我们在发出请求后,根据一定的规则,在服务列表中找到请求对应的处理服务(服务提供的能力是不同的),这称为服务的路由。
负载均衡
负载均衡简单的讲就是对于负载较高的服务,往往对应着一个集群。当请求到来的时候,为了将请求均衡的负载到合适的服务器,负载均衡程序将通过相应的规则,选取一台服务器进行访问,这个过程被称为负载均衡。而这些服务器提供的服务是相同的。
一张图看清区别
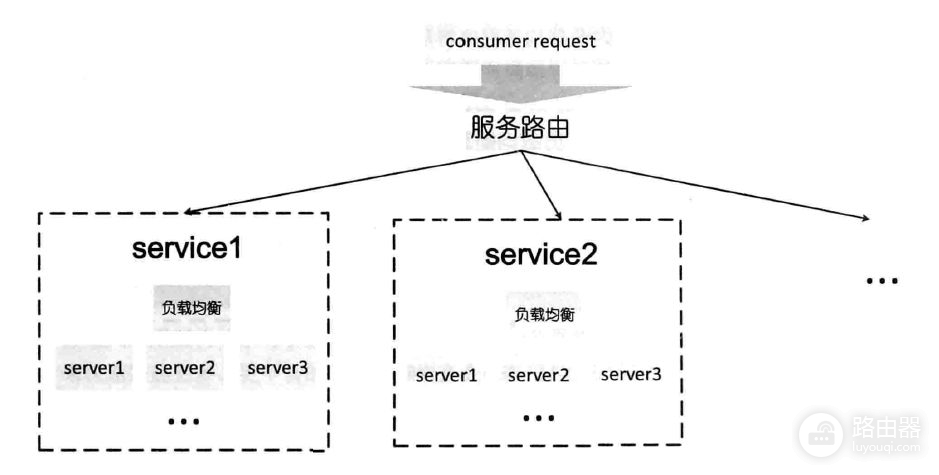
从图中我们便可以清晰地看出。服务路由规则是将请求分发到不同的服务集群中的。而负载均衡,则是在同一个服务集群中进行请求分发的方式。
我们提到的一致性hash,就是负载均衡的一种解决方案。但是我们上面提到的问题,其实是路由层面的问题。两者有本质性的差别。
Dubbo中的路由规则和负载均衡
在Dubbo中,路由规则的实现方式有:
- 条件路由。支持以服务或 Consumer 应用为粒度配置路由规则。
- 标签路由。以 Provider 应用为粒度配置路由规则。 这两种方法都可以解决上面提到的问题。
详见:https://dubbo.apache.org/zh/docs/advanced/routing-rule/
而Dubbo的负载均衡方式就更多了:
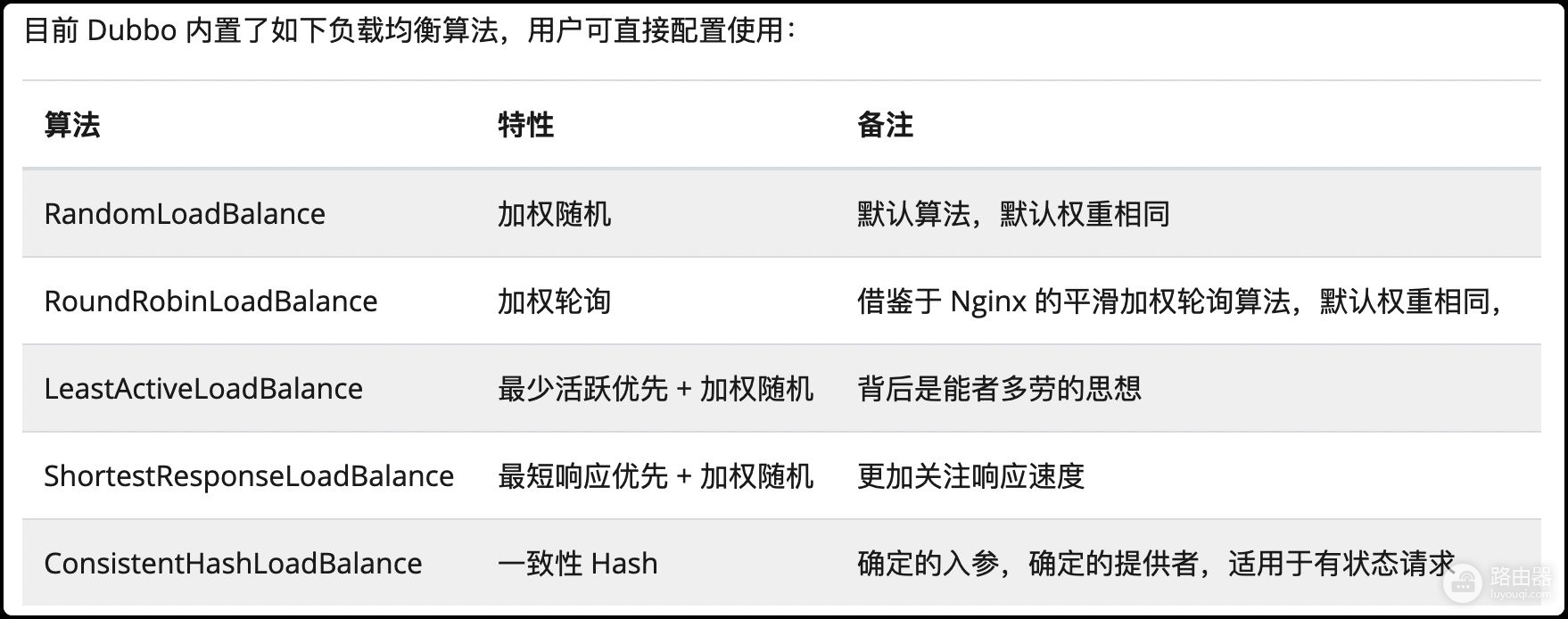
我们通过负载均衡算法,可以解决请求在同一个集群下的不同机子访问不平衡的问题。
详见:https://dubbo.apache.org/zh/docs/advanced/loadbalance/
写在最后
大家在学习的过程中,对于学习的知识,对应解决的是哪一种问题要多加注意。不同的领域有其对应的解决方案,但这些方案在其他领域是否适用也要学会辨别和区分。













